
Introduction
Disks refer to storage devices used to store data persistently. The operating
system manages these disks to store files, applications, and system data. Disks can be internal (such as HDDs and SSDs) or
external (like USB drives and external HDDs).
Disk scheduling is done by operating systems to schedule I/O requests arriving for the disk.
Disk scheduling is also known as I/O Scheduling. The main purpose of disk scheduling algorithm is
to select a disk request from the queue of IO requests and decide the schedule when this request will be processed.
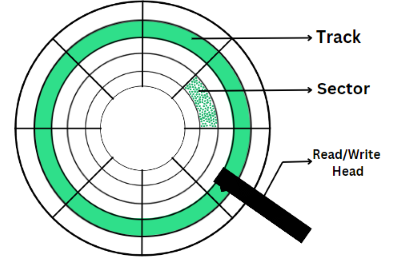
Some important terms related to disk scheduling:-
- Tracks: Tracks are concentric rings on the surface of a disk platter. They are used to organize data on the disk.
- Sectors: Sectors are the smallest storage units on a disk. A sector typically holds 512 bytes or 4096 bytes of data. The operating system reads and writes data to the disk in sector-sized chunks.
- Read/Write Head: The read/write head is the component of a disk drive that reads data from and writes data to the disk platters. It moves radially across the disk to access different tracks.
- Head Value: The head value refers to the specific read/write head being used in a multi-head disk system.
- Seek Time: It is the time taken in locating the disk arm to a specified track where the read/write request will be satisfied.
Seek Time = (Time to cross 1 cylinder(track))*(No of cylinder(track) crossed)
- Seek Operation: Seek Operation refers to the movement of the disk's read/write head to the specific cylinder (track) where the data needs to be read or written.
- Rotational Latency: It is the time taken by the desired sector to rotate itself to the position from where it can access the R/W heads.
- Transfer Time: It is the time taken to transfer the data.
- Disk Access Time: Disk access time is given as,
Disk Access Time = Rotational Latency + Seek Time + Transfer Time
- Disk Response Time: It is the average of time spent by each request waiting for the IO operation.
- Starvation: Starvation occurs when a process or request is perpetually denied necessary resources because other processes are continually being given priority.
- Throughput: Throughput is a measure of how many I/O operations (or requests) are completed in a given period. Higher throughput means more requests are being serviced, which generally implies better performance.
Types
- FCFS(First Come First Serve): It is one of the simplest disk scheduling algorithm.
In FCFS scheduling, the requests for input/output (I/O) operations are serviced in the order they arrive, without any
reordering based on the location of data on the disk or the current position of the disk head.
Example:
- Order of request is: (82, 170, 43, 140, 24, 16, 190)
- Current position of Read/Write head is: 50
- So, total overhead movement = (82-50) + (170-82) + (170-43) + (140-43) + (140-24) + (24-16) + (190-16) = 642
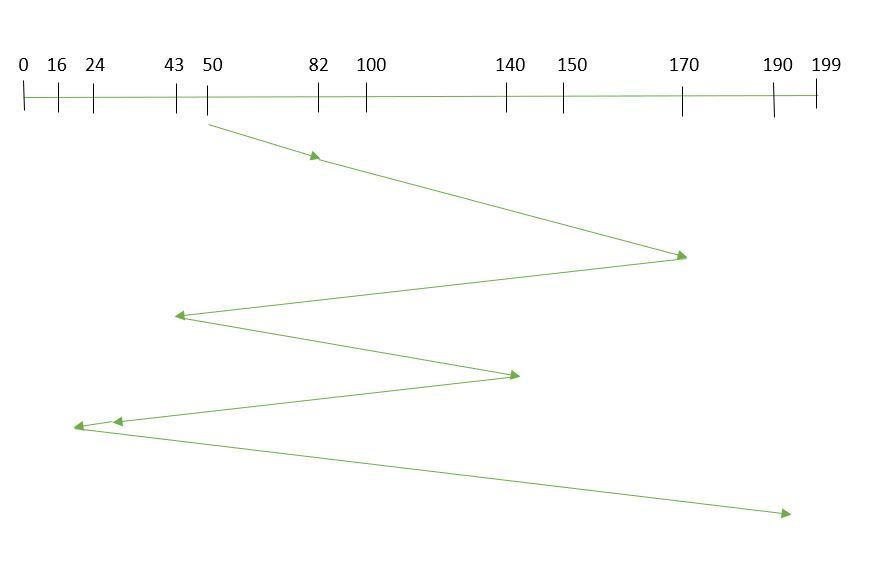
Fig. 2 FCFS Disk Scheduling
Advantages
- It is easy to implement and understand, making it suitable for systems where complexity is a concern.
- It ensures fairness in accessing the disk, as all requests are treated equally.
- No indefinite postponement.
Disadvantages
- Required more seek time and waiting time.
- May not provide the best possible service.
- SSTF(Shortest Seek Time First): This algorithm selects
the disk I/O request which requires the least disk arm movement from its
current position regardless of the direction.
Example:
- Order of request is: (82, 170, 43, 140, 24, 16, 190)
- Current position of Read/Write head is: 50
- So, total overhead movement = (50-43) + (43-24) + (24-16) + (82-16) + (140-82) + (170-140) + (190-170) = 208
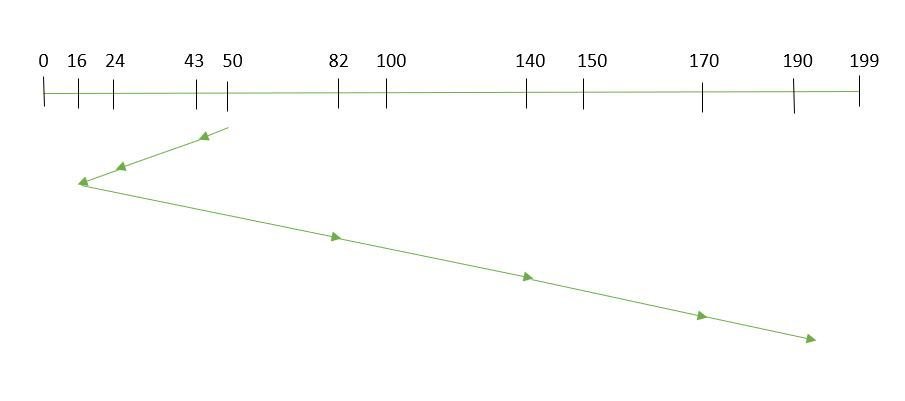
Fig. 3 SSTF Disk Scheduling
Advantages
- Very efficient in seek move.
- Less average response time and waiting time.
- Improved throughput.
Disadvantages
- It may lead to starvation of requests that are located far from the current disk head position.
- Overhead to find out the closet requirement.
- SCAN: In this algorithm, head starts at one end of the disk &
moves towards the other end. It is also called elevator algorithm. The direction of the head is reversed and
process continues.
Example:
- Order of request is: (82, 170, 43, 140, 24, 16, 190)
- Current position of Read/Write head is: 50
- It is also given that the disk arm should move “towards the larger value”
- So, total overhead movement = (199-50) + (199-16) = 332
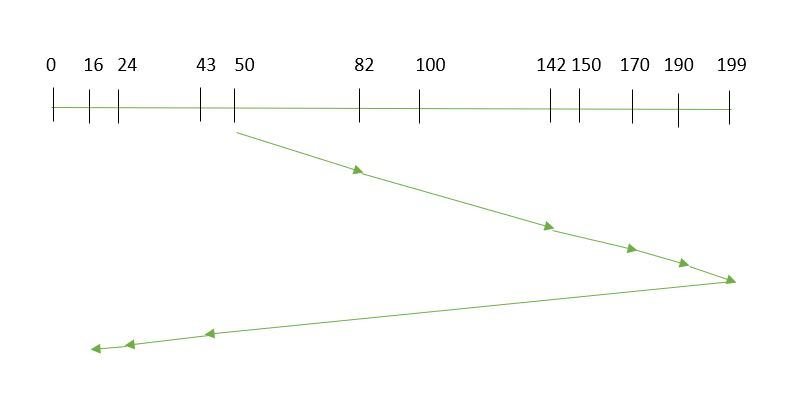
Fig. 4 Scan Disk Scheduling
Advantages
- Low variance and average waiting time.
- Simple easy to understand.
Disadvantages
- Long waiting time for location just visited by head.
- C-SCAN (Circular SCAN): In this algorithm, head starts at one end of the disk &
moves towards the other end. The direction of the head is reversed and
head reaches first end without satisfying
any request.
Example:
- Order of request is: (82, 170, 43, 140, 24, 16, 190)
- Current position of Read/Write head is: 50
- It is also given that the disk arm should move “towards the larger value”
- So, total overhead movement = (199-50) + (199-0) + (43-0) = 391
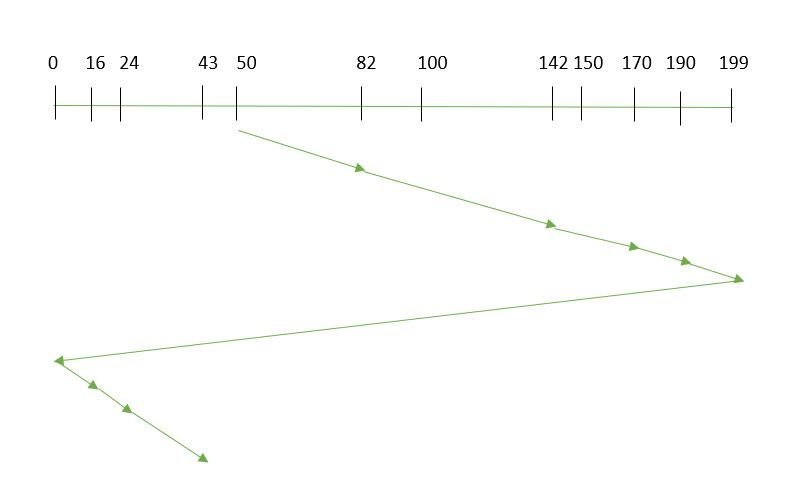
Fig. 5 C-Scan Disk Scheduling
Advantages
- Provide uniform waiting time.
- Better Response Time.
Disadvantages
- More Risk as compared to simple Scan Algorithm.
Comparison
| Feature | FCFS | SSTF | Scan | C-Scan |
|---|---|---|---|---|
| Concept | Serves requests in the order they arrive. | Selects the request with the shortest seek time from the current head position. | Moves the head in one direction, serving requests along the way. Reverses direction at the end. | Similar to SCAN, but jumps to the beginning when reaching the end. |
| Pros | Simple and fair. | Minimizes average seek time. | Better performance than FCFS and no starvation. | Better performance than SCAN and efficient for fragmented data. |
| Cons | High seek times and poor performance. | Starvation and thrashing. | Longer seek times than SSTF. | Longer seek times for requests near the beginning when the head is at the end. |
| Suitability | Low disk activity and uniform data distribution. | Moderate disk activity and seek time optimization. | Moderate disk activity and balance fairness and performance. | High disk activity and fragmented data. |
| Average Seek Time | High | Low | Moderate | Moderate |
| Starvation | No | Yes | No | No |
| Throughput | Low | Moderate | Moderate | High |
| Implementation Complexity | Easy | Moderate | Moderate | Moderate |
Application
- Operating Systems: To manage file systems and optimize disk I/O operations efficiently.
- Database Management Systems: To handle large volumes of data access requests and ensure quick data retrieval.
- Real-Time Systems: Where predictable and low-latency disk access is crucial for performance.
- High-Performance Computing: To maximize throughput and minimize access time for large data sets.